Article originally posted by myself at https://medium.com/oracledevs/how-the-chaos-engineering-will-guarantee-the-resilience-of-your-services-20a01471fa8e
If you are more a “video person“, I have this same content published on my YouTube channel in a playlist with 9 videos:
[embedyt] https://www.youtube.com/embed?listType=playlist&list=PL-zC883FSfIpnmhCamE22lLFItUYyx_nz&v=cioc-rWmcZI[/embedyt]
There’s a fact: sometimes, something goes wrong. Are your services prepared for this moment?
It isn’t only about to predict any kind of failure, but how to deal with the unpredictable. Ask yourself: my services are resilient?
In this article, we will discuss how chaos engineering provides the approaches to let your application ready for whatever it comes. In other words, how chaos can bring order to your services.
Some thoughts around chaos, failures, and resilience
Before going into a deeper dive into our subject, it’s important to state some definitions and assumptions over it.
Chaos Engineering is the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production.
This definition came from the “Principles of Chaos Engineering” (1) website, a collaborative set of definitions and thoughts about this discipline.
Resilience is the ability of a system to adapt itself due to changes, failures, and anomalies
A good example of resilience is when your Gmail works in classic mode. You can’t use a lot of its features, but it’s still working. It’s using graceful degradation to provide resilience to the application.
Sometimes something will fail. Even with the best systems.
You can build the best infrastructure. You can code the best code. Even then, something will go wrong at some point.
Inject failures on purpose before they happen unexpectedly. Find the weaknesses and fix them.
If failures will happen anyway, why not use it to improve your services capabilities to face them?
Where should I inject chaos?
Usually, our services are a set of different technologies, environments, and resources. All of them have different roles and, usually, all of them can fail. So if you want to start trying them, there are some suggestions where you could start.
Application layer
Your code has features, behaviors, and flows. Try them.
Cache layer
Modern applications rely more and more on caches. What if a cache isn’t available? What if it’s been building while you are trying to access it? Is there any alternative repository in case of failure?
Database layer
Shutdown the database, take your popcorn, sit down, and watch it.
Cloud layer
In the Cloud Native age, are your Cloud Native applications ready to… cloud issues? What if an instance goes down? What if a policy is changed by someone else? What a whole datacenter just dies?
The 5 phases of Chaos Engineering
For a quick summary of the phases of Chaos Engineering, you can check this image:
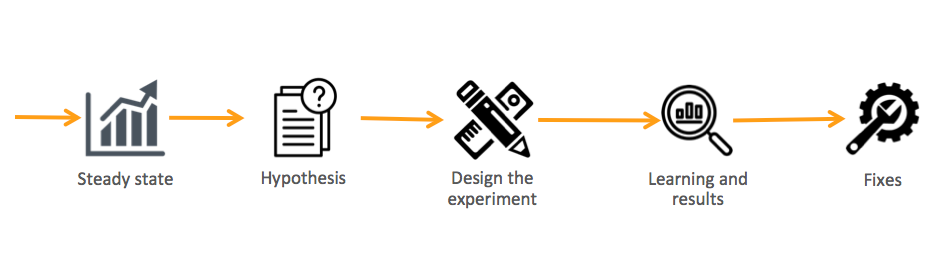
Phase 1: Steady-state
It’s the regular behavior of your service based on its business metric.
Business metric it *the* metric! Is that metric that shows you the real experience that your end users have with your system.
The example below is taken from an article (2) from Netflix:
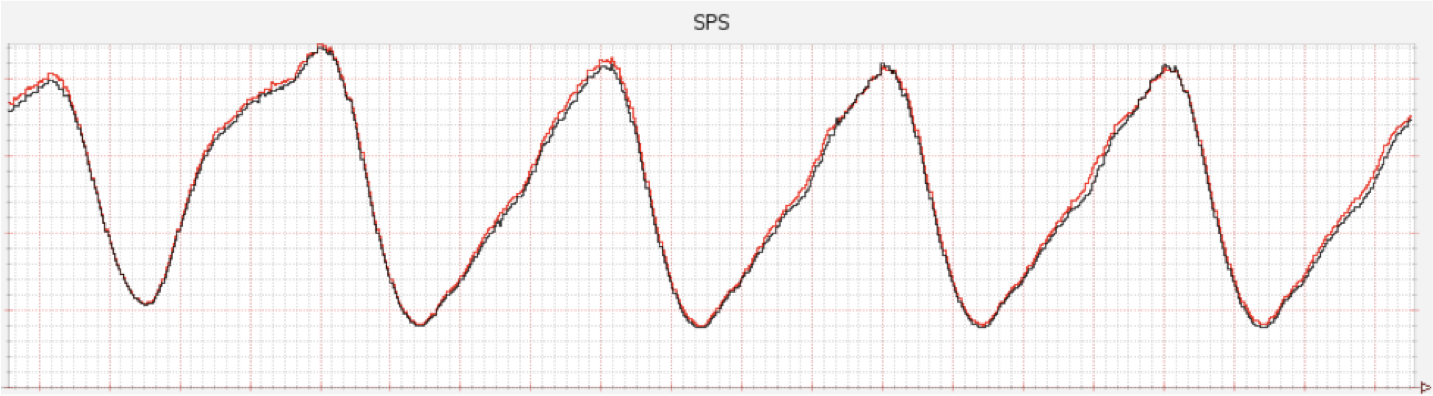
The graphic shows the steady-state of SPS (Streams Per Second) at Netflix. This is their business metric. So they can track its behavior week after week until they find its regular usage. That’s a steady-state.
So whenever you are monitoring your system or, in our case, planning and executing your fail injections, all your tracking will be based on the business metric.
Phase 2: Hypothesis
After you have your business metric defined and know your steady-state, then it’s time to start asking questions.
What if:
- A service return 404?
- Does the database stop work?
- Requests increases unexpectedly?
- Latency increases by 100%?
- Does a container stop working?
- A port becomes inaccessible?
Of course, these are just examples. The important part is: make questions that you don’t know the answer (this should be obvious, right?). So, for example, if you already know that your service doesn’t have a high availability environment, doesn’t make any sense to test it. First, build it, then try possibilities around it.
Phase 3: Design the experiment
Now that you have a hypothesis that you don’t know the answer and are worthy of trying, start designing your experiments.
Some best practices around it are:
- Start small
- Make it closest possible to the production environment
- Minimize the blast radius
- Have an emergency stop button
One way to implement it is by using a kind of canary deployment approach:
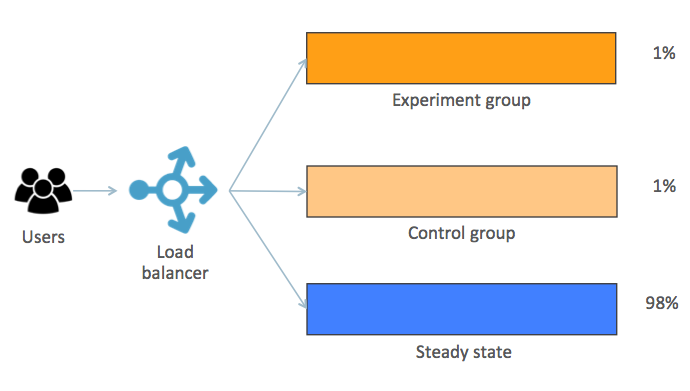
Understand what is going on in the image:
- Steady-state: regular behavior
- Control group: a small set of users that are under the same conditions of the steady-state
- Experiment group: has the same size as the Control group, but it’s where the chaos will be injected
We have the Control and Experiment groups with the same size for the sake of comparative results at the end of the experiment.
To separate both groups from the steady-state flow you can, for example, include a property in the request header and use it. It can be done in the load balancer without any changes in the application itself.
Phase 4: Learning and results
At the end of the experiments, it’s time to collect the results and get the lessons learned. So here you will evaluate:
- How much time to detect the failure?
- How much time to someone be notified?
- How much time to start the graceful degradation?
- How much time to recovery (partial and full)?
- How much time to be back to a steady-state?
Phase 5: Fixes
Well… this is the self-explanatory part!

Keep in mind that when working in a chaos engineering approach, it’s all about learning from failure. That’s why you create them on purpose, in a controlled and managed environment.
We learn from failure, not from success — Dracula, Bram Stoker
Kubernetes & Chaos Engineering
Makes sense to use Kubernetes to talk about chaos engineering for a couple of reasons:
- K8s has some natives features for resilience
- It manages pods status and performs restarts based on it
- K8s clusters can have nodes — and so pods — distributed in different regions/AZs/ADs
So it’s a great environment to play around with chaos!
Also, there is a good set of tools that you can use to apply chaos using Kubernetes. Some of them are:
- Istio
- Chaos Toolkit
- Chaos Monkey
- Kube Monkey
Let’s briefly check them.
Istio
Istio has pretty nice features to help inject failures into your service just by working on its YAML file. For example:
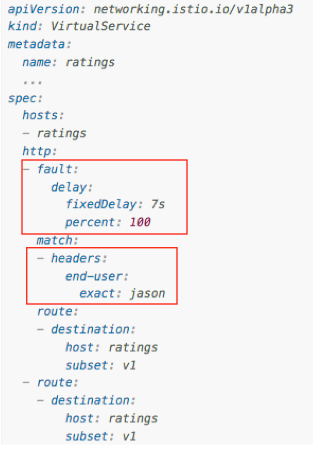
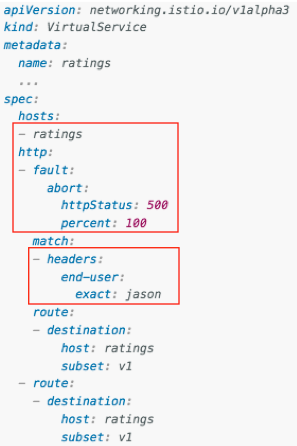
There’s a whole doc provided by Istio team regarding fault injection at (3).
Chaos Toolkit
It has a set of drivers to a lot of cloud providers and platforms as shown in the image below:
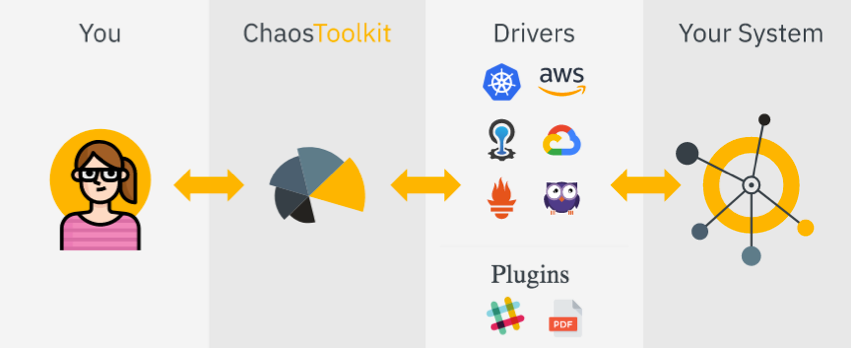
The good part is that it’s fully based on the 5 Phases of Chaos Engineering covered in this post.
And it also has specific support for Kubernetes (5) based on YAML files:
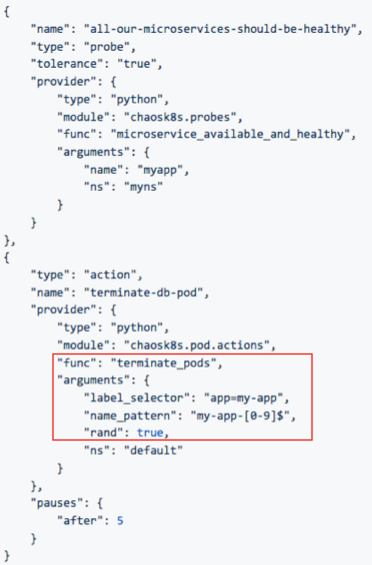
You can check for more information on it’s Github repository at (4).
Chaos Monkey
It kills containers and/or virtual machines in the production environment. If you are using Spinnaker (6), it’s already integrated out of the box.
You can check for more information on it’s Github repository at (7).
Kube Monkey
It’s based on Kube Monkey but made specifically for Kubernetes. Your service needs to opt-in for its pods being killed:
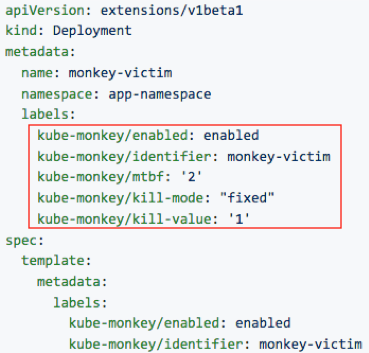
You can also schedule it to execute accordingly to your needs:
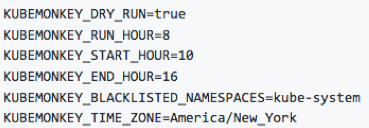
It’s important also to define the namespaces that are blacklisted (as in the image above). So, for example, you won’t run into a risk to kill the management pods of your cluster (even if some nuts opt them in).
Check more details about it at (8).
Your turn!
Getting started into chaos engineering world is all about… starting! As mentioned in this post, start small… baby steps for the win.
Choose the smallest and easiest possible part of your services and apply the principles covered here. If you need any help, just say it!
References
(1) http://principlesofchaos.org/
(2) https://medium.com/netflix-techblog/sps-the-pulse-of-netflix-streaming-ae4db0e05f8a
(3) https://istio.io/docs/tasks/traffic-management/fault-injection/
(4) https://github.com/chaostoolkit/chaostoolkit
(5) https://github.com/chaostoolkit/chaostoolkit-kubernetes
(7) https://github.com/netflix/chaosmonkey
(8) https://github.com/asobti/kube-monkey
This very informative. all of us want to have a successful projects but sometimes unexpected gonna happen and we need to find a solution for that and turn of for opportunities. This is really good post because its telling us what to do in times of failure. environmental engineering, mechanical engineering, software engineering, etc. for the future engineers, Hope they will apply this
😉