A multi-step agentic workflow is a stateful process. One agent validates an order, another waits on a human decision, a third finalizes it; each step reads and writes shared state, and the whole run can last seconds, minutes, or days. Anything that runs that long eventually gets interrupted. A deploy rolls the pods. The node scales down. The JVM crashes. The question that decides whether a workflow is safe to operate is plain: when the process comes back, what happens to the run that was in flight?
Until you have an answer, the workflow is a liability in any environment where the process can restart. LangChain4j 1.13.0 (released alongside its twenty-third beta) lands the piece that gives you one: it makes the execution state of an agentic system persistable and recoverable.
What actually gets persisted
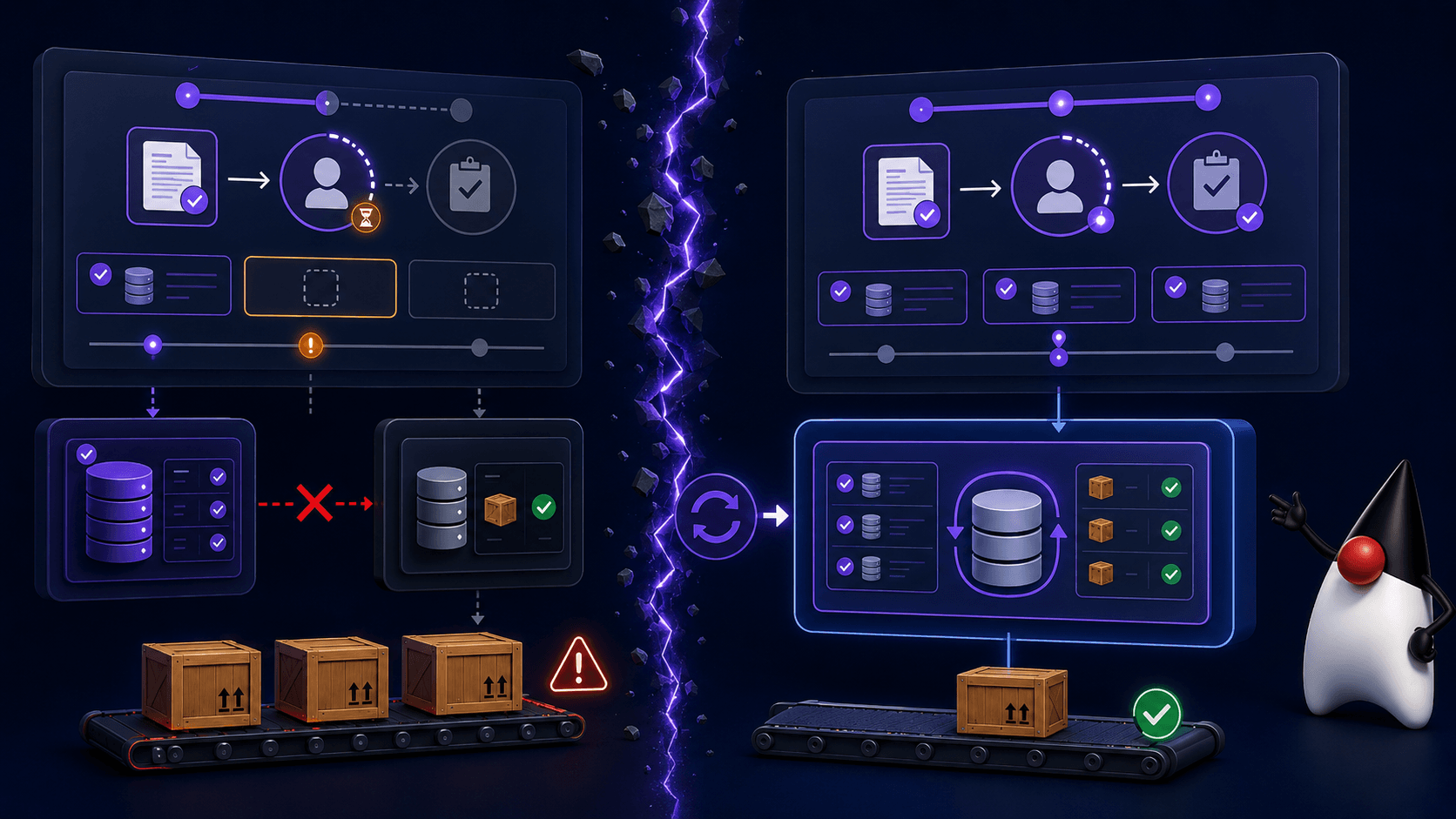
Recoverability rests on two mechanisms working together, and the difference between them is the whole point.
The first is per-step checkpointing. After each agent invocation, the current AgenticScope (the shared state every agent reads from and writes to) is checkpointed to a configured store. Everything an agent wrote with writeState is durably persisted, so the intermediate results of a half-finished run survive the process that produced them.
The second is planner execution state. The execution loop saves the planner’s internal position, which agent in the sequence has been reached, so that on recovery the workflow resumes from the correct step instead of restarting from the beginning.
Persisting the data alone would not be enough. If you only saved the scope’s contents, a recovered run would still re-execute every step from the top, re-calling models and re-triggering side effects that already happened. Saving the planner’s position is what makes resume actually mean resume: the run continues from the step it was on, with the state it had already accumulated.
The case that makes this concrete: human-in-the-loop
The clearest place this earns its keep is a workflow that pauses for a person. Take the order-processing shape from the LangChain4j docs: an agent validates the order, then the run hits an approval gate built with AgenticServices.humanInTheLoopBuilder(), whose responseProvider returns a PendingResponse for a key like "manager-approval". At that point the run is parked. The manager might approve in five minutes or after a long weekend, and across that gap the process can restart any number of times for reasons that have nothing to do with this order.
When the decision arrives, resume takes one of two shapes. In-flight, while the same process is still up, you call completePendingResponse("manager-approval", "APPROVED by manager") on the AgenticScope, typically from a REST endpoint that received the decision. After a restart, you reload the scope with workflow.getAgenticScope("order-12345"), write the human decision into it, and re-invoke the workflow with the same id; the planner picks up at the gated step and runs the rest.
InfoQ’s Java roundup names the two classes behind this as RecoverabilityIT and PendingResponse. PendingResponse is the type your code touches directly: it is the placeholder the scope holds while it waits for an answer, and it is what completePendingResponse fills in. A long-running approval gate is exactly the step a restart used to break: while the process waited, a restart sent the run back to the beginning. With the scope and the planner position both persisted, the wait can outlive the process.
The real decision: where the state lives
The store is a seam. Recoverability activates when an AgenticScopeStore is configured and the scope is made persistent through a memory id (the @MemoryId annotation). Which store you put behind that seam is an architectural decision you should make deliberately rather than default into.
The reason it matters is that a checkpoint rarely stands alone. Each agent step usually has side effects in your own systems: it reserves inventory, inserts a row, calls a downstream service. If the agent’s checkpoint lives in one store and the step’s business write lives in another, a crash in the window between them leaves the two disagreeing. The business row says the inventory was reserved, while the scope says the step never completed. On resume, the planner re-runs a step whose side effect already landed, and now you have a double reservation.
The rule that falls out of this is straightforward: persist the AgenticScope where its checkpoint and the step’s business write can commit or fail together. If your agent step writes to a relational database inside a transaction, the cheapest correct option is to checkpoint into that same database, so both participate in the same transactional boundary and a crash can never leave one ahead of the other. A separate store (a cache, a document database) is viable only when each step is idempotent on resume, so that re-running a step that already committed does no harm. That idempotency is a property you design into each step, not one the framework hands you.
So the order of operations is: decide which steps are idempotent, then decide where the scope lives. Reaching for the most convenient store first and discovering the consistency gap in production is the expensive way to learn this.
Optional agents: surviving missing inputs
Recoverability keeps a workflow alive across process restarts. Optional agents keep it alive across missing inputs. By default, when an agent cannot find one of its required arguments in the scope, the entire system fails with a MissingArgumentException. Marking an agent with .optional(true) tells the workflow to skip that agent silently when its inputs are absent and keep going.
For cases where you want to react rather than skip, there is errorHandler, which turns an ErrorContext into an ErrorRecoveryResult: detect the missing argument, write a sensible default into the scope, and return ErrorRecoveryResult.retry(), or return ErrorRecoveryResult.throwException() to stop. A workflow that has to survive restarts also has to survive partial inputs, and these two give you a way to express that at the orchestration level instead of wrapping every step in defensive branching.
HibernateContentRetriever: the durable agent meets existing data
Durable state answers half of what a production agent needs. The other half is the data. A workflow that resumes at exactly the right step is still of little use if it can only reason over what was in the prompt. Retrieval is how the agent reaches your data, and the default story for retrieval has been a vector store: embed your content, stand up a second system, and keep it synchronized with your system of record.
1.13 adds another path. HibernateContentRetriever retrieves data through HQL (Hibernate Query Language) queries. In RAG terms it is a ContentRetriever, the same abstraction every retrieval source implements: you hand it a query, it returns a list of Content. That means it slots into the same retrieval position a vector store would occupy, so the agent’s retrieval step does not care which one is behind it. What changes is where the content comes from. Instead of an embedding index, it uses a ChatModel to generate HQL from a natural language query and runs that HQL over the entities you already map with Hibernate.
The architectural consequence is the reason to care. A durable agent can now retrieve over the relational data your application already owns, through the same persistence layer, datasource, and transactions your services already use, without standing up and synchronizing a separate vector store for that retrieval path. For a large share of enterprise data (orders, customers, tickets, inventory) that is already structured and already queryable, that takes a whole subsystem out of the design. Semantic vector search still earns its place for genuinely unstructured text. This gives you a relational retrieval path for the data that was never unstructured to begin with, mapped to the same entities your existing code already trusts.
What the release actually hands you
Taken together, 1.13 supplies the two primitives a long-running agentic workflow needs to hold up under real operations: execution state that survives a restart and resumes at the correct step, and retrieval that reaches the data you already keep in a relational database. Neither removes the design work. Recoverability still asks you to decide where the AgenticScope lives and which steps are idempotent. HibernateContentRetriever still asks you to decide which retrieval belongs in HQL and which belongs in vectors. The release gives you the seams; the consistency model behind them is yours to choose.
That division of labor is the right one, and the choices it leaves you are the ones worth settling before the first workflow takes real traffic, not after a restart has already replayed a step you thought had only run once.